Thoughts on the AI systems in Horizon: Zero Dawn

Horizon: Zero Dawn is perhaps the most exciting game I have ever played as an adult. It is incredibly immersive, and its game world is so beautifully constructed that I wish I was born in that world. Its music is excellent. Its character design, clothing, body language and facial animation are all excellent. Most memorably is its combat system and the combat experience against herds of machines. After my first playthrough on the very-hard difficulty level, my amazement led me to researching the AI design of this game.
Quoting Tommy Thompson’s writing on Gamasutra:
In addition, groups select machines to attack the player based not just on whether the HTN planner thinks an it can execute a specific behaviour, but also whether that attack is going to be interesting. If all machines simply attacked the player at once, then you would die a horrible death pretty quickly. As such the combat systems use an approach similar to that found in Halo 3 where it balances which enemy attacks you based on how interesting that attack will be in the context of combat.
This requires an action selection utility function that is calculates how interesting it would be for that machine to attack. This is based on the current machines state, whether the player is aware of that machine in proximity, how close it is to the player and the amount of damage it has received and dished out. This becomes a precondition of the HTN planning system, and aims not only to provide some challenge, but also to inject some variety into the combat.
Perhaps more critically, when the HTN planner is asked to generate actions for attack groups, while an attack is being selected the other machines in the group are also being given movement behaviours to circle the player and wait their turn. This is done deliberately to create opportunities for the player to exploit, either attacking a passive machine or countering the one that just attacked you. In time you’ll slowly be able to wear them down, largely because the combat system is deliberately leaving itself open to attack.
From first-hand experience, the effect of combat machines taking turns to attack and circling Aloy when not attacking is both relieving and intense; it is relieving when the duration between consecutive attacks is manageable, and it is intense when mistakes are made by myself (bad positioning or bad shooting) such that a long string of attacks approach Aloy without pause; the machine circling when not attacking also asserts a constant psychological pressure on me as I deal with the active attacker and feel that someone is staring at my back and taking their time to find my vulnerability. Enjoyably, this pressure is reduced by the fact that machine-specific game music is played when Aloy is interacting with a given type of machine, and that the intensity of the music serves as a key indicator of the machine’s state (alert, aggression etc). In short, the combat experience in this game is truly fantastic and memorable.
Yet, this (taking turns to attack and circling when not attacking) is obviously a hard-coded behavior for a herd of combat machines to deal with the human aggressor - through curating action macros stored in the hierarchical task network planner (HTN) for AI agent to query and execute. The important question here is: how can we make AI generate those interesting behaviors that lead to memorable experiences i.e. can the action macros themselves as well as the coordination policy (“attack” macro to one machine and “circle” macro to all others) be learned? In other words, without human injecting heuristics, how can AI learn to be truly interesting?
Note that for AI to defeat human is not difficult; given a clear winning condition and fixed game rules, AI can defeat the best human players in such a complex game as Starcraft II. The interesting problem is: how can the machine learn about interestingness tabula rasa?
Possibilities:
- Formalize interestingness into a cost function.
- Acquire or construct an “interestingness signal” during realtime gameplay to be used by RL as the reward.
Perhaps the term interestingness is too conceptually coarse. We need to break it down into different aspects and create a variety of knobs so that we can create a diverse set of interesting AIs, each interesting in a distinct way. In contrast, difficulty level has long been designed as a linear construct and player has clear expectation of what it means - the higher the difficulty, the more stressful or the more times I will die before the player conquers the game.
From HZD’s own presentation by Arjen Beij we have a better glimpse into how the developer defined interestingness for Aloy’s combat (solo or with a group of human ally NPCs) against machines:

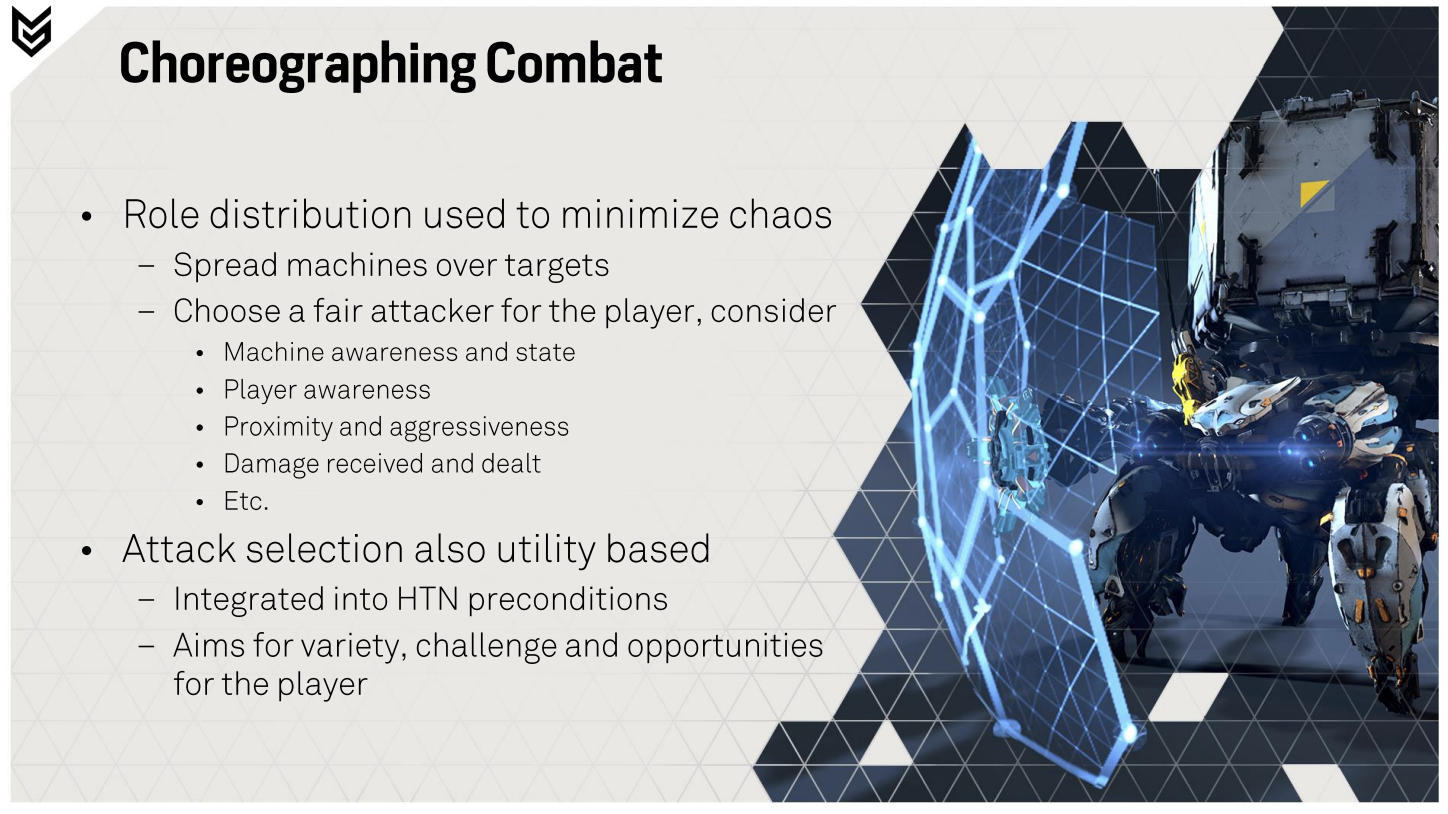
We can see that both the role distribution within a group of machine and the attack selection for a given attacker machine are both utility-based. We can further summarize the metrics behind such utility calculation: minimize chaos and optimize fairness when performing role distribution; balance variety, challenge and opportunities when performing attack selection. These metrics are all understandable, and the resulting combat experience is indeed interesting (intense, manageable, dynamic, and rewarding). The question is, can these metrics be learned? Furthermore, can AI not only learn the metrics for role distribution and attack selection, but also learn the hierarchical architecture of decision-making itself (group->role->action->navigation->animation)?
I believe it is possible. Jeff Clune puts it well:
One motivation for a learn-as-much-as-possible approach is the history of machine learning. There is a repeating theme in machine learning (ML) and AI research. When we want to create an intelligent system, we as a community often first try to hand-design it, meaning we attempt to program it ourselves. Once we realize that is too hard, we then try to hand-code some components of the system and have machine learning figure out how to best use those hand-designed components to solve a task. Ultimately, we realize that with sufficient data and computation, we can learn the entire system. The fully learned system often performs better. It also is more easily applied to new challenges (i.e. it is a more general solution).
I further intuit that, given the variety of tastes for interestingness among human gamers, the dominant social organization of scientific effort (i.e. the time horizon and research scale of academic publications) could perhaps successfully theorize it but will not be able to invent / discover it.